[JAVA] 쓰레드(Thread)
STEP#01. 쓰레드( Thread )란?
쓰레드( Thread )란? java라는 명령어를 실행해서 결과를 출력하고, 끝내는것을 의미한다.
하지만 웹 어플리케이션처럼 한번 실행해 놓고, 계속 기능들을 제공하는 프로그램을 만든다면
쓰레드라는 것이 무엇인지 알아야 한다.
java 프로그램을 사용하여 뒤에 클래스 이름을 붙이고, 엔터를 치면 적어도 하나의 JVM이 시작된다.
보통 이렇게 JVM이 시작되면 하나의 자바 프로세스( Process )가 시작한다.
이 프로세스라는 울타리 안에서 여러 개의 쓰레드 라는 것이 아둥바둥 살게된다.
즉, 하나의 프로세스 내에 여러 쓰레드가 수행된다.
하지만, 거꾸로 여러 프로세스가 공유하는 하나의 쓰레드가 수행되는 일은 절대 없다.
어떤 프로세스든 간에 쓰레드가 하나 이상 수행된다.
정리하자면, java 명령어를 사용하여 클래스를 실행시키는 순간 자바 프로세스가 시작되고,
main( ) 메소드가 수행되면서 하나의 쓰레드가 시작되는 것이다.
만약 많은 쓰레드가 필요하다면, 쓰레드를 생성해 주면 된다.
자바를 사용하여 웹 어플리케이션을 제공할 때에는 Tomcat 같은 WAS( Web Application Server )를 사용한다.
이 WAS도 똑같이 main 쓰레드에서 생성한 쓰레드들이 수행되는 것이다.
그렇다면, 왜 쓰레드라는 것을 만들었을까? 프로세스 하나 시작하려면 많은 자원( resource )을 필요로 한다.
만약 하나의 작업을 동시에 수행하려고 할 때 여러 개의 프로세스를 띄워서 실행하면 각각 메모리를 할당해 주어야만 한다.
JVM은 기본적으로 아무런 옵션없이 실행하면 OS마다 다르지만, 32MB ~ 64MB( Mega Btye )의 물리 메모리를 점유한다.
그에 반해서, 쓰레드를 하나 추가하면 1MB 이내의 메모리를 점유한다.
그래서, 쓰레드를 "경량 프로세스( Lightweight process )"라고 부른다.
그리고, 요즘은 PC급의 장비도 두개 이상의 코어( core )가 달려 있는 멀티 코어 시대다.
어떤 작업을 할 때 단일 쓰레드로 실행하는 것보다는 다중 쓰레드로 실행하는 것이 더 빠른 시간에 결과를 제공해 준다.
따라서, 보다 빠른 처리를 할 필요가 있을 때, 쓰레드를 사용하면 보다 빠른 계산을 처리할 수도 있다.
STEP#02. Runnable 인터페이스와 Thread 클래스
쓰레드를 생성하는 것은 크게 두 가지 방법이 있다.
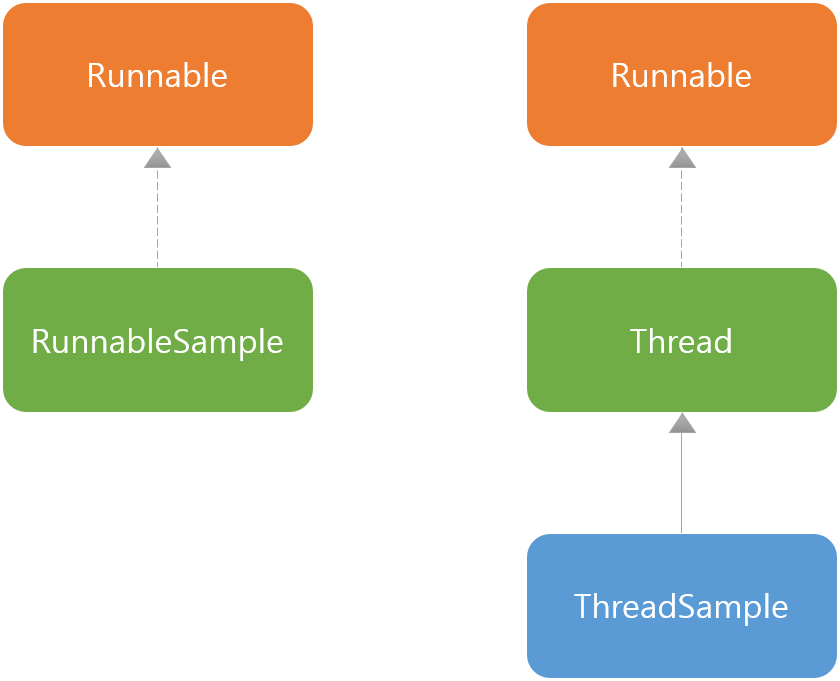
하나는 러너블( Runnable ) 인터페이스를 사용하는 것이고, 다른 하나는 쓰레드( Thread ) 클레스를 사용하는 것이다.
쓰레드 클래스는 러너블 인터페이스를 구현한 클래스이므로, 어떤 것을 적용하는냐 차이만 있다.
러너블 인터페이스와 쓰레드 클래스는 모두 java.lang 패키지에 있다. 따라서,
이 인터페이스나 클래스를 사용할 때에는 별도로 import할 필요가 없다.
러너블 인터페이스에 선언되어 있는 메소드는 단지 하나다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
| void | run( ) | 쓰레드가 시작되면 수행되는 메소드 |
바로 run( ) 이라는 메소드이며 리턴 값은 없다.
그에 반해 쓰레드 클래스는 매우 많은 생성자와 메소드를 제공한다.
러너블 인터페이스를 구현한 RunalbeSample 클래스의 예제를 다음고 같이 만들어 보자.
// @File RunnableSample.java
package e.thread;
public class RunnableSample implements Runnable {
public void run() {
System.out.println( "This is RunnableSample's run( ) method." );
}
}
예제는 아주 간단하게 되어 있다.
쓰레드가 시작되면 한 줄을 출력하고 그 쓰레드는 끝난다.
이번에는 Thread 클래스를 확장한 예제를 살펴보자.
// @File ThreadSample.java
package e.thread;
public class ThreadSample extends Thread {
public void run() {
System.out.println( "This is ThreadSample's run() method." );
}
}
마찬가지로 이 예제도 매우 간단하다.
RunnableSampe 클래스와 ThreadSample 클래스는 모두 쓰레드로 실행할 수 있다는 공통점이 있다.
하지만, 이 두개의 쓰레드 클래스를 실행하는 방식은 다르다.
쓰레드를 수행하는 RunThreads라는 클래스를 다음과 같이 만들자.
// @File RunThreads.java
package e.thread;
public class RunThreads {
public static void main(String[] args) {
RunThreads threads = new RunThreads();
threads.runBasic();
}
public void runBasic() {
RunnableSample runnable = new RunnableSample();
new Thread( runnable ).start(); // Runnable 실행 방법
ThreadSample thread = new ThreadSample();
thread.start(); // Thread 실행방법
System.out.println( "RunThreads.runBasic( ) method is ended." );
}
}
다른 부분은 지금까지 살펴본 main( ) 메소드를 가진 클래스와 동일하므로, 별도의 설명은 필요 없을 것이다.
쓰레드를 실행시키는 굵은 글씨로 표시한 runBasic( ) 메소드를 살펴보자.
객체를 생성한 부분은 별다른 차이가 없다. 하지만, 그 밑에 두 줄은 눈여겨볼 필요가 있다.
- 쓰레드가 시작하면 수행되는 메소드는 run( ) 메소드다.
- 쓰레드를 시작하는 메소드는 start( ) 이다.
다시 말해서, 러너블 인터페이스를 구현하거나 쓰레드 클래스를 확장할 때에는 run( ) 메소드를 시작점으로 작성해야만 한다.
그런데, 쓰레드를 시작하는 메소드는 run( )이 아닌 start( )라는 메소드다.
여러분들이 start( ) 메소드를 만들지 않아도, 알아서 자바에서 run( ) 메소드를 수행하도록 되어 있다.
먼저 RunnableSample을 시작한 코드를 보자.
new Thread( runnable ).start();
러너블 인터페이스를 구현한 RunnableSample 클래스 쓰레드로 바로 시작할수는 없다. 따라서,
이와 같이 쓰레드 클래스의 생성자에 해당 객체를 시작해 주어야만 한다.
그 다음에 start() 메소드를 호출하면 쓰레드가 시작된다.
다음으로 ThreadSample을 시작한 코드를 보자.
thread.start();
ThreadSample 클래스의 객체에 바로 start() 메소드를 호출하였다.
쓰레드 클래스를 바로 확장한 클래스는 이와 같이 사용할 수 있다.
이렇게 2가지 방법을 제공하는 이유는, 자바에서는 확장을 하나의 클래스에만 할 수 있다.
만약 어떤 클래스가 어떤 다른 클래스를 extends를 사용해 확장해야 하는 상황인데, 쓰레드로 구현해야 한다.
게다가 그 부모 클래스는 쓰레드를 확장하지 않았다. 어떻게 해야 할까?
자바에서 쓰레드 클래스를 확장해야만 쓰레드로 구현 할 수 있는데,
다중 상속이 불가능하므로 해당 클래스를 쓰레드로 만들 수 없다.
하지만, 인터페이스는 여러 개의 인터페이스를 구현해도 전혀 문제가 발생하지 않는다.
따라서, 이러한 경우에는 러너블 인터페이스를 구현해서 사용하면 된다.
정리하자면, 쓰레드 클래스가 다른 클래스를 확장할 필요가 있을 경우에는 러너블 인터페이스를 구현하면 되며,
그렇지 않은 경우에는 쓰레드 클래스를 사용하는 것이 편하다.
지금까지 살펴본 클래스들의 관계를 클래스 다이어그램으로 나타내면 다음과 같다.
이제 RunThreads 클래스를 컴파일하고 실행해 보자.
# java> RunThreads.java
This is RunnableSample's run( ) method.
RunThreads.runBasic( ) method is ended.
This is ThreadSample's run() method.
왜 이러한 결과가 나올까?
기본적으로 프로그램은 순차적( Sequential ) 구조로 실행되어 있다.
곧 한 줄의 코드가 있으면, 그 줄의 실행이 끝날때까지 기다렸다가 다음 줄이 실행된다.
다음의 아주 간단한 코드를 보자.
int a = 1;
a = a + 1;
System.out.print( a );a에 1을 할당하고 1을 더했으니, 출력하는 결과는 2가 된다.
이와 같이 일반적인 메소드 내에서는 호출한 순서대로 수행되기 때문에 어떤 순서로 실행되는지를 알 수 있다.
그런데, 쓰레드라는 것을 start() 메소드를 통해서 시작했다는 것은,
프로세스가 아닌 하나의 쓰레드를 JVM에 추가하여 실행한다는 것이다.
쓰레드를 기동시키는 runBasic() 메소드에서 runnable이라는 객체를 쓰레드 클래스의 start() 메소드로 시작한다.
이때 시작한 start() 메소드가 끝날 때까지 기다리지 않고, 그 다음줄에 있는 thread라는 객체의 start() 메소드를 실행한다.
이 줄도 마찬가지로, 새로운 쓰레드를 시작하므로 run() 메소드가 종료될 때까지 기다리지 않고, 바로 다음 줄로 넘어간다.

이처럼, 여러분들이 쓰레드를 구현할 때 start( ) 메소를 호출하면,
쓰레드 클래스에 있는 run( ) 메소드의 내용이 끝나든, 끝나지 않든 간에
쓰레드를 시작한 메소드에서는 그 다음 줄에 있는 코드를 실행한다.
좀더 이해하기 쉽게 다른 예제를 하나 더 살펴보자.
package thread;
public class RunThreads2 {
public static void main(String[] args) {
RunThreads threads = new RunThreads();
threads.runBasic();
}
public void runBasic2() {
RunnableSample []runnable = new RunnableSample[5];
ThreadSample []thread = new ThreadSample[5];
int loop;
for( loop = 0; loop < 5; loop++ ) {
runnable[ loop ] = new RunnableSample();
thread[ loop ] = new ThreadSample();
}
new Thread( runnable[ loop ] ).start(); // Runnable 실행 방법
thread[ loop ].start(); // Thread 실행방법
System.out.println( "RunThreads.runBasic( ) method is ended." );
}
}방금 전에 살펴본 메소드와 다른 점은 각각 5개의 RunnableSample과 ThreadSample의 객체를 생성하여 실행한다는 점이다.
이렇게 하면 총 10개의 쓰레드가 수행된다.
main( ) 메소드에서 이 메소드만 수행하도록 한 후의 결과를 살펴보자.
한 번만 실행해 보지 말고, 여러 번 싫애해 보기 바란다.
PC 사양에 따라서 결과가 달라질 수도 있겠지만,이
와 같이 메소드를 수행할 때마다 결과가 달라지는 것을 볼 수 있겠지만,
이와 같이 메소드를 수행할 때마다 결과가 달라지는 것을 볼 수 있을 것이며,
해당 결과dml runbasic2( )메소드의 가장 마지막 줄에 있는 출력문이 가장 마지막에 수행되지 않은 것을 볼 수 있다.
그렇다면 새로 생성한 쓰레드는 언제 끝날까? 바로, run( ) 메소드가 종료되면 끝난다.
만약 run( ) 메소드가 끝나지 않으면, 직접 실행한 어플리케이션은 끝나지 않는다.
STEP#03. Thread 클래스의 생성자
Thread 클래스는 다음과 같이 8개의 생성자가 있다.
| 생성자 | 설명 |
| Thread( ) | 새로운 쓰레드를 생성한다. |
| Thread( Runnable target ) | 매개 변수로 받은 target 객체의 run( ) 메소드를 수행하는 쓰레드를 생성한다. |
| Thread( Runnable target, String name ) | name이라는 이름을 갖는 쓰레드를 생성한다. |
| Thread( String name ) | name이라는 이름을 갖는 쓰레드를 생성한다. |
| Thread( ThreadGroup group, Runnable target ) | 매개 변수로 받은 group의 쓰레드 그룹에 속하는 target 객체의 run( ) 메소드를 수행하는 쓰레드를 생성한다. |
| Thread( ThreadGroup group, Runnable target, String name ) | 매개 변수로 받은 group의 쓰레드 그룹에 속하는 target 객체의 run( ) 메소드를 수행하고, name이라는 이름을 갖는 쓰레드를 생성한다. |
| Thread( ThreadGroup group, Runnable target, String name, long stackSize ) | 매개 변수로 받은 group의 쓰레드 그룹에 속하는 target 객체의 run( ) 메소드를 수행하고, name이라는 이름을 갖는 쓰레드를 생성한다. 단 해당 쓰레드 스택의 크기는 stackSize 만큼만 가능하다. |
| Thread( ThreadGroup, String name ) | 매개 변수로 받은 group의 쓰레드 그룹에 속하는 name 이라는 이름을 갖는 쓰레드를 생성한다. |
이 부분에 대해서 알아보기 전에 쓰레드의 이름을 먼저 알아보자.
모든 쓰레드는 이름이 있다. 만약 아무런 이름을 지정하지 않으면, 그 쓰레드의 기본 이름은 "Thread-n"이다.
여기서 n은 쓰레드가 생성된 순서에 따라 증가한다.
그렇지 않고, 다른 쓰레드 이름을 지정한다면, 해당 쓰레드는 별도의 이름을 가지게 된다.
만약 쓰레드 이름이 겹친다고 해도 예외나 에러가 발생하지는 않는다.
어떤 쓰레드를 생성할 때 쓰레드를 묶어 놓을 수 있다.
그게 바로 쓰레드 그룹( ThreadGRroup )이다. 이렇게 쓰레드의 그룹을 묶으면
쓰레드 그룹 클래스에서 제공하는 여러 메소드를 통해서 각종 정보를 얻을 수 있다.
그리고, 밑에서 두번째 생성자에 있는 stackSize라는 값은 스택( stack )의 크기를 이야기 한다.
쓰레드에서 얼마나 많은 메소드를 호출하는지, 얼마나 많은 쓰레드가 동시에 처리되는지
JVM이 실행되는 OS의 플랫폼에 따라서 매우 다르다.
경우에 따라서 이 값이 무시될 수도 있다.
package e.thread;
public class NameThread extends Thread {
public NameThread() { }
public void run() { }
}
NameThread라는 클래스가 있으며, Thread 클래스를 확장했다.
이렇게 아무런 조치를 취하지 않으면, 아무 매개 변수도 없는 Thread( ) 생성자를 사용하는 것과 동일하다.
만약 쓰레드의 이름을 "ThreadName"으로 지정하고 싶다면, 이 NameThread의 생성자는 다음과 같이 변경하면 된다.
public NameThread() {
super( "ThreadName" );
}
그러면, Thread( String name )을 호출한 것과 동일한 효과를 보게 되는 것이다.
한걸음 더 나아가서, 이렇게 코드에 "ThreadName"이라고 지정해주면, 이 쓰레드 객체를 몇십 개를 만들어도
"ThreadName"이라는 동일한 이름을 가지게 된다.
이러한 단점을 피하려면 생성자를 다음과 같이 변경하면 된다.
public NameThread( String name ) {
super( name );
}
그리고 쓰레드를 실행할 때에는 run( ) 메소드가 진입점이고, 쓰레드를 시작시킬 때에는 start( ) 메소드를 호출해야 한다.
이 메소드들에는 매개 변수가 없다.
그런데, 쓰레드를 시작할 때 어떤 값을 전달하고 싶으면 어떻게 할 수 있을까?
예를 들어서, 쓰레드를 시작할 때 100이라는 숫자를 넘겨주고, 그 값으로 곘나을 해야할 일이 생겼을 때를 이야기 하는것이다.
매겨 변수가 없는 run( )과 start( ) 메소드만 갖고 백번 생각해도 답은 나오지 않는다.
쓰레드 객체를 생성할 때 매개 변수를 받고, 인스턴스 변수로 사용한다면 가능하다.
package e.thread;
public class NameThread extends Thread {
private int calcNumber;
public NameThread( String name, int calcNumber ) {
super( name );
this.calcNumber = calcNumber;
}
public void run() {
calcNumber++;
}
}
이렇게 사용하면, calcNumber라는 값을 동적으로 지정하여 쓰레드를 시작할 수 있다.
STEP#04. 많이 사용되는 sleep( ) 메소드
쓰레드 클래스에는 디프리케이티드( deprecated )된 메소드도 많고, 스태틱( static ) 메소드도 많이 있다.
디프리케이티드( deprecated )된 메소드는 "더 이상 사용하지 않는 것" 이라는 의미다.
그리고, 스태틱( static ) 메소드는 객체를 생성하지 않아도 사용할 수 있는 메소드를 말한다.
다시 말해서, 쓰레드에 있는 스태틱 메소드는 대부분 해당 쓰레드를 위해서 존재하는 것이 아니라,
JVM에 있는 쓰레드를 관리하기 위한 용도로 사용된다.
물론 예외도 있다. 그 예외중 하나가 sleep( ) 메소드다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
| static void | sleep( long millis ) | 매개 변수로 넘어온 시간( 1 / 1,000 초 )만큼 대기한다. |
| static void | sleep( long millis, int nanos ) | 첫번째 매개 변수로 넘어온 시간( 1 / 1,000 초) + 두번째 매개 변수로 넘어온 시간( 1 / 1,000,000,000 초 ) 만큼 대기한다. |
run( ) 메소드가 끝나지 않으면, 어플리케이션은 끝나지 않는다.( 다만, 데몬 쓰레드라는 것은 예외다. )
정말 그런지, sleep( ) 메소드를 사용하여 확인해 보자.
package e.thread;
public class EndlessThread extends Thread {
public void run() {
while( true ) {
try {
System.out.println( System.currentTimeMillis() );
Thread.sleep( 1000 );
}
catch( InterruptedException e ) {
e.printStackTrace( );
}
}
}
}
run( ) 메소드 안을 보면 while( true )라고 되어 있다.
이렇게 while 문 내의 조건이 true이면, 이 while문은 break를 호출하거나, 예외를 발생시키지는 않는 한 멈추지 않는다.
while 문 내의 문자응ㄹ 보면 현재 시간을 밀리초 단위로 출력하고,
쓰레드 클래스의 sleep( ) 메소드를 static 하게 호출하여 1초간 멈춘다.
이렇게 되면, 이 프로그램은 Window 터미털 창에서 Ctrl + c 키를 누를 때까지
1초에 한번씩 현재 시간을 밀리초 단위로 계속 출력한다.
( 이클립스 console의 경우는 빨간버튼( Terminate ) 클릭 )
그리고, 한 가지 더 고려해야 한다. 바로 여러분들이 Thread.sleep( ) 메소드를 사용할 때에는
항상 try - catch로 묶어 주어야만 한다는 것이다.
왜냐하면 sleep( ) 메소드는 InterruptedException을 던질 수도 있다고 선언되어 있기 때문이다.
여기서 "적어도"라는 말은 반드시 InterruptedException은 아니더라도, Exception과 같이 상위에 있는
예외를 사용해도 된다는 의미다.
이제 EndlessThread 클래스에 다음의 endless( ) 메소드를 추가한 후
main( ) 메소드에서 이 메소드만 수행하도록 하고 결과를 확인해 보자.
package thread;
public class RunThreads {
public static void main(String[] args) {
RunThreads threads = new RunThreads();
// threads.runBasic();
threads.endless(); // endless() 메소드만 실행
}
public void runBasic() {
RunnableSample runnable = new RunnableSample();
new Thread( runnable ).start(); // Runnable 실행 방법
ThreadSample thread = new ThreadSample();
thread.start(); // Thread 실행방법
System.out.println( "RunThreads.runBasic( ) method is ended." );
}
public void endless() {
EndlessThread thread = new EndlessThread();
thread.start();
}
}
아마도 다음과 같이 밀리초가 화면에 지속적으로 출력될 것이다.
1604230781112
1604230782112
1604230783113
1604230784113
1604230785114
1604230786114
1604230787115
1604230788115
// --- 이하 생략 ---
다시 말해서, main( ) 메소드의 수행이 끝나더라도, main( ) 메소드나, 다른 메소드에서 시작한 쓰레드가 종료하지 않으면
해당 자바 프로세스는 끝나지 않는다. 하지만, 다음 절에서 설명하는 데몬( demon ) 쓰레드는 예외다.
Thread 클래스의 주요 메소드를 살펴보자
이제 본격적으로 Thread 클래스에 선언된 static도 아니고 deprecated도 아닌 메소드 중 주요 메소드에 대해서 살펴보자.
Thread 클래스의 주요 메소드는 크게 보면 쓰레드의 속성을 확인하고, 지정하기 위한 메소드와 쓰레드의 상태를 통제하기 위한 메소드로 나눌 수 있다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
| void | run( ) | |
| long | getId( ) | JVM에서 자동으로 생성해준다. |
| String | getName( ) | 쓰레드의 이름을 리턴한다. |
| void | setName( String name ) | 쓰레드의 이름을 지정한다. |
| int | getPriority( ) | 쓰레드의 우선순위를 확인한다. |
| void | setPriority( int newPriority ) | 쓰레드의 우선순위를 지정한다. |
| boolean | isDaemon( ) | 쓰레드가 데몬인지 확인한다. |
| void | setDaemon( boolean on ) | 쓰레드의 데몬 여부를 지정한다. |
| StackTraceElement[ ] | getStackTrace( ) | 쓰레드의 스택 정보를 확인한다. |
| Thread.State | getState( ) | 쓰레드의 상태를 확인한다. |
| ThreadGroup | getThreadGroup( ) | 쓰레드의 그룹을 확인한다. |
여기서, 쓰레드의 우선 순위( Priority )라는 것이 처음 나왔다.
쓰레드 우선순위라는것은 말 그대로, 대기하고 있는 상황에서 더 먼저 수행할 수 있는 순위를 말한다.
대부분 이 값은 기본값으로 사용하는 것을 권장한다.
앞에서, 데몬 쓰레드가 아닌 사용자 쓰레드를 데몬으로 지정하면, 그 쓰레드가 수행되고 있든 수행되지 않고 있든 상관 없이
JVM이 끝날 수 있다. 단, 해당 쓰레드가 시작하기( start( ) 메소드가 호출되기 )전에 데몬 쓰레드로 지정되어야만 한다.
쓰레드가 시작한 다음에는 데몬으로 지정할 수 없다.
위에 있는 쓰레드 클래스의 모든 메소드를 사용할 일은 그리 많지 않다.
하지만, 가끔 확인을 위해 필요하므로 예제를 통해서 간단히 살펴보자.
RunThreads 클래스에 다음의 메소드를 추가하자.
package thread;
public class RunThreads {
public static void main(String[] args) {
RunThreads threads = new RunThreads();
// threads.runBasic();
// threads.endless();
threads.checkThreadProperty();
}
// @see 생략
public void runBasic() { }
// @see 생략
public void endless() { }
public void checkThreadProperty() {
ThreadSample thread1 = new ThreadSample();
ThreadSample thread2 = new ThreadSample();
ThreadSample daemonThread = new ThreadSample();
// @ 쓰레드의 아이디를 출력
System.out.println( "thread1 id = " + thread1.getId() );
System.out.println( "thread2 id = " + thread2.getId() );
// @ 쓰레드의 이름을 출력
System.out.println( "thread1 name = " + thread1.getName() );
System.out.println( "thread2 name = " + thread2.getName() );
// @ 쓰레드의 일련 번호( 우선순위 )를 출력
System.out.println( "thread1 priority = " + thread1.getPriority() );
daemonThread.setDaemon( true );
System.out.println( "thread1 isDaemon = " + thread1.isDaemon() );
System.out.println( "daemonThread isDaemon = " + daemonThread.isDaemon() );
}
}
RunThreads 클래스의 main( ) 메소드에서 이 메소드만 수행하도록 한 수 결과를 확인해 보자.
수행 결과는 다음과 같다.
thread1 id = 11
thread2 id = 12
thread1 name = Thread-0
thread2 name = Thread-1
thread1 priority = 5
thread1 isDaemon = false
daemonThread isDaemon = true
첫 두줄을 보면 쓰레드의 아이디를 출력하였고,
그 다음 두줄을 보면 쓰레드의 이름이 Thread-0, Thread-1과 같이 자동으로 Thread 뒤에 일련 번호가 추가되는 것을 볼 수 있다.
그리고, 우선순위가 있는데, 이 우선순위는 기본값이 5이다.
이처럼 쓰레드에 대한 각종 상태를 확인할 수 있다.
참고로, 쓰레드 API를 잘 살펴보면 다음과 같이 우선순위에 관계 있는 3개의 상수가 있다.
| 상수 | 값 및 설명 |
| MAX_PRIORITY | 가장 높은 우선순위이며, 그 값은 10이다. |
| NORM_PRIORITY | 일반 쓰레드의 우선순위 이며, 그 값은 5다. |
| MIN_PRIORITY | 가장 낮은 우선순위이며, 그 값은 10이다. |
만약 우선순위를 정할 일이 있다면, 숫자로 정하는 것보다. 이 상수를 이용할 것을 권장한다.
그리고, 이 결과의 마지막을 보면 daemonThread라는 쓰레드 객체를 데몬 쓰레드를 지정하고 난 후 그 내용을 출력한 것을 볼 수 있다.
이렇게 쓰레드가 수행하기 전에 데몬 여부를 지정해야만 그 쓰레드가 데몬 쓰레드로 인식된다.
간단한 예제를 통해서 데몬 쓰레드의 특징을 살펴보자. 다음과 같이 DemonThread 클래스를 만들자.
package e.thread;
public class DaemonThread extends Thread {
public void run() {
try {
Thread.sleep( Long.MAX_VALUE );
}
catch( Exception e ) {
e.printStackTrace();
}
}
}
특별한 내용은 없고, 앞서 배운 Thread 클래스의 sleep( ) 메소드를 사용하여 long의 최대값만큼 대기하도록 해 놓았다.
즉, 별다른 일이 없는 한 해당 쓰레드는 끝나지 않을 것이다.
이 쓰레드 클래스의 객체를 생성하여 다음의 메소드를 RunThreads 클래스에 만들자.
package e.thread;
public class RunThreads {
public static void main(String[] args) {
RunThreads threads = new RunThreads();
// threads.runBasic();
// threads.endless();
// threads.checkThreadProperty();
threads.runDaemonThread();
}
public void runBasic() { }
public void endless() { }
public void checkThreadProperty() { }
public void runDaemonThread() {
DaemonThread thread = new DaemonThread();
// thread.setDaemon( true );
thread.start();
}
}
일단 데몬 쓰레드로 지정하지 말고 실행해 보자.
( main( ) 메소드에서 이 메소드만 수행하도록 한 후 어떻게 되는지 살펴보자. )
분명히 제대로 코드를 작성했다면, 아무런 메시지도 뿌리지 않고 해당 프로그램은 끝나지 않을 것이다.
이제 Ctrl + c를 눌러 해당 프로세스를 종료하자.
( 이클립스 console의 경우는 빨간버튼( Terminate ) 클릭 )
runDaemonThread( ) 메소드에 seDaemon( true ); 데몬 쓰레드를 한줄 추가하자.
package e.thread;
public class RunThreads {
public static void main(String[] args) {
RunThreads threads = new RunThreads();
// threads.runBasic();
// threads.endless();
// threads.checkThreadProperty();
threads.runDaemonThread();
}
public void runBasic() { }
public void endless() { }
public void checkThreadProperty() { }
public void runDaemonThread() {
DaemonThread thread = new DaemonThread();
thread.setDaemon( true ); // setDaemon( ) 데몬 메소드 추가
thread.start();
}
}
이렇게 해 변경하고 다시 실행해 보자.
앞에서 실행했을 떄와 다른 점은 단지 데몬 쓰레드로 지정한 것 뿐인데,
프로그램이 sleep( ) 메소드가 끝날 때까지 대기하지 않고, 그냥 끝나 버리는 것을 알 수 있다.
다시 말해서, 데몬 쓰레드는 해당 쓰레드가 종료되지 않아도 다른 실행중인 일반 쓰레드가 없다면 멈춰 버린다.
STEP#05. 쓰레드와 관련이 많은 동기화( synchronized )
쓰레드 클래스에서 제공하는 메소드를 살펴보기 전에 싱크로나이즈( synchronized )에 대해서 살펴보자.
이 단어는 자바의 예약어중 하나다. 다시 말해서, 변수명이나, 클래스명으로 사용할 수 없다.
그런데 Thread 클래스를 설명하다가 왜 갑자기 싱크로나이즈를 설명할까?
왜냐하면 쓰레드와 싱크로나이즈는 뗄레야 뗄 수 없는 관계이기 때문이다.
앞에서, "쓰레드에 안전하다( Thread safe )"라고 이야기를 몇번 했다. 어떤 클래스나 메소드가 쓰레드에 안전하려면,
싱크로나이즈를 사용해야만 한다.
싱크로나이즈는 두 가지 방법으로 상요할 수 있다.
하나는 메소드 자체를 싱크로나이즈로 선언하는 방법( synchronized methods )과
다른 하나는 메소드 내의 특정한 문장만 싱크로나이즈로 감싸는 방법( synchronized statements )이다.
먼저 메소드를 싱크로나이즈로 선언하는 것에 대해서 알아보자.
메소드를 싱크로나이즈로 선언하려면 메소드 선언문에 synchronized를 넣어주면 된다.
만약 다음과 같이 plus( ) 라는 메소드가 있다면,
public void plus( int value ) {
amount += value;
}
이 메소드를 싱크로나이즈로 선언하려면 다음과 같이 하면된다.
public synchronized void plus( int value ) {
amount += value;
}
이 한 단어가 있는 것과 없는 것의 차이는 크다.
만약 이 싱크로나이즈라는 단어가 메소드 선언부에 있으면, 해당 객체의 이 메소드에 2개의 쓰레드가 접근하든,
100개의 쓰레드가 접근하든 간에 한 순간에는 하나의 쓰레드만 이 메소드를 수행하게 된다.
예를 들어 평소에 100만원에 팔던 물건을 1만원에 100개를 판다고 했을 때 사람들이 줄을 서지 않고,
너도 나도 물건을 가져가게 놔 둔다면 가장 늦게 온 사람도 물건을 사는 경우도 발생하고, 가장 먼저 온 사람이 물건을 못 살수도 있다.
게다가, 서로 자기가 가져가겠다고 싸움도 발생할 수 있고, 하나의 물건을 잡아 당기다가 물건이 파손되어 팔지 못할 수 도 있다.
자바에서도 마찬가지다. "여러 쓰레드가 한 객체에 선언된 메소드에 접근하여 데이터를 처리하려고 할 때"
동시에 연산을 수행하여 값이 꼬이는 경우가 발생할 수 있다.
단, 메소드에서 공유하는 인스턴스 변수를 수정하려고 할 때에만 이러한 문제가 생긴다.
매개 변수나 메소드에서만 사용하는 지역변수만 다루는 메소드는 전혀 싱크로나이즈로 선언할 필요가 없다.
이제 실습을 통해 싱크로나이즈가 어떻게 실행되는지 살펴보자.
먼저 CommonCalculate 클래스를 만들자.
package e.thread.sync;
public class CommonCalculate {
private int amount;
public CommonCalculate() {
amount = 0;
}
public void plus( int value ) {
amount += value;
}
public void minus( int value ) {
amount -= value;
}
public int getAmount() {
return amount;
}
}
이 클래스는 간단한 연산을 수행하는 메소드를 제공한다. amount라는 인스턴스 변수가 선언되어 있다.
그리고 plus( )라는 메소드에서는 매개 변수로 받은 값을 더하고, minus( )라는 메소드에서는 매개 변수로 받은 값을 뺀다.
마지막에 있는 getAmount( )라는 메소드는 현재의 amount( )값을 출력한다.
이 클래스의 객체를 매개 변수로 받아서 처리하는 다음의 쓰레드가 있다.
package thread.sync;
public class ModifyAmountThread extends Thread {
private CommonCalculate calc;
private boolean addFlag;
public ModifyAmountThread( CommonCalculate calc, boolean addFlag ) {
this.calc = calc;
this.addFlag = addFlag;
}
public void run() {
for( int loop = 0; loop < 10000; loop++ ) {
if( addFlag ) {
calc.plus( 1 );
} else {
calc.minus( 1 );
}
}
}
}
생성자에서 방금 만든 ComonCalculate 클래스의 객체를 받고, run( ) 메소드에서는 addFlag가 true면 1을 더하고,
addFlag가 false면 1을 빼는 연산을 수행한다.
덧셈이나 뺄셈 연산을 만번 수행하고 나서, 해당 쓰레드는 종료한다.
이제 이 쓰레드를 실행하는 RunSync 라는 쓰레드 실행 코드를 보자.
package thread.sync;
public class RunSync {
public static void main( String[] args ) {
RunSync runSync = new RunSync();
runSync.runCommonCalculate();
}
public void runCommonCalculate() {
// 앞서 만든 CommonCalculate라는 클래스의 객체를 CALC라는 이름으로 생성했다.
CommonCalculate calc = new CommonCalculate();
// ModifyAmountThread라는 클래스의 객체를 생성할 때 calc를 매개 변수로 넘겨주고,
// plus( ) 메소드만 수행하도록 true를 두번째 매개변수로 넘겼다.
ModifyAmountThread thread1 = new ModifyAmountThread( calc, true );
ModifyAmountThread thread2 = new ModifyAmountThread( calc, true );
// 각각의 쓰레드를 시작한다.
thread1.start();
thread2.start();
try {
// try - catch 블록 안에서는 join( ) 이라는 메소드를 가각의 쓰레드에 호출한다.
// 여기서 join( ) 메소드는 쓰레드가 종료될때까지 기다리는 메소드다.
thread1.join(); // ④
thread2.join(); // ④
// join( )이 끝나면 calc 객체의 getAmount( ) 메소드를 호출한다.
// getAmount( ) 메소드의 호출 결과는 join( ) 메소드 수행 이후이므로,
// 모든 쓰레드가 종료된 이후의 결과다.
System.out.println( "Final value is " + calc.getAmount() ); // ⑤
}
catch ( InterruptedException e ) {
e.printStackTrace();
}
}
}
코드가 좀 길긴 하지만 천천히 내용을 살펴 보면 그리 복잡하지는 않다.
runCommon Calculate( ) 메소드만 보면 된다.
결론적으로 RunSync 클래스의 runCommonCalculate( ) 메소드가 수행된 후에는
두개의 쓰레드에서 하나의 객체에 있는 amount라는 int타입의 값에 1을 만 번 더한 결과를 출력한다.
즉, 정상적인 상황이라면, 결과는 20,000이 출력되어야만 한다.
일단 한 번 RunSync 클래스를 실행해보면 다음과가 같은 결과가 출력된다.
Final value is 11459
예상한 결과가 아니다. 처음 수행할 때에만 그럴 수도 있으니,
main( ) 메소드를 다음과 같이 변경하여 여러 번 반복하도록 변경하자.
package thread.sync;
public class RunSync {
public static void main( String[] args ) {
RunSync runSync = new RunSync();
for( int loop = 0; loop < 5; loop++ ) {
runSync.runCommonCalculate();
}
}
public void runCommonCalculate() {
// 앞서 만든 CommonCalculate라는 클래스의 객체를 CALC라는 이름으로 생성했다.
CommonCalculate calc = new CommonCalculate();
// ModifyAmountThread라는 클래스의 객체를 생성할 때 calc를 매개 변수로 넘겨주고,
// plus( ) 메소드만 수행하도록 true를 두번째 매개변수로 넘겼다.
ModifyAmountThread thread1 = new ModifyAmountThread( calc, true );
ModifyAmountThread thread2 = new ModifyAmountThread( calc, true );
// 각각의 쓰레드를 시작한다.
thread1.start();
thread2.start();
try {
// try - catch 블록 안에서는 join( ) 이라는 메소드를 가각의 쓰레드에 호출한다.
// 여기서 join( ) 메소드는 쓰레드가 종료될때까지 기다리는 메소드다.
thread1.join(); // ④
thread2.join(); // ④
// join( )이 끝나면 calc 객체의 getAmount( ) 메소드를 호출한다.
// getAmount( ) 메소드의 호출 결과는 join( ) 메소드 수행 이후이므로,
// 모든 쓰레드가 종료된 이후의 결과다.
System.out.println( "Final value is " + calc.getAmount() ); // ⑤
}
catch ( InterruptedException e ) {
e.printStackTrace();
}
}
}
위와같이 다섯 번 반복한 후의 결과를 살펴보자.
Final value is 15462
Final value is 16588
Final value is 12833
Final value is 14940
Final value is 12238
만약 ModifyAmountThread라는 쓰레드에서 반복하는 횟수가 적을수록 결과는 예상한 값에 가깝거나,
예상한 대로 출력될 것이다. 하지만, 반복 횟수가 많아질수록, 그 결과는 정상적인 결과와 멀어진다.
왜냐하면, 그 이ㅠ는 plus( ) 라는 메소드 때문이다. 이 메소드는 다른 쓰레드에서 작업하고 있다고 하더라도,
새로운 쓰레드에서 온 작업도 같이 처리한다. 따라서, 데이터가 꼬일 수 있다.
CommonCalculate클래스의 plus( ) 메소드를 다시 살펴보자.
public void plus( int value ) {
amount += value;
}
어떻게 보면 이 메소드는 한줄이다.
그런데, value 값을 amount에 더하는 작업은 간단해 보여도, 내부적으로는 그리 간단하지 않다.
실제로 이 메소드의 내용을 풀어 쓰면 다음과 같다.
amount = amount + value;
연산은 우측 항의 결과가 좌측항에 있는 amount에 담는다.
예를 들어 우측 항에 있는 amount가 1이고, value가 1일 경우, 정상적인 경우라면 좌측 항의 결과에는 2가 된다.
그런데 좌측 항에 2라는 값을 치환하기 전에 다른 쓰레드가 또 들어와서 이 연산을 수행하려고 한다.
아직 amount의 값이 2가 안 된 상황에서 amount의 값은 1이다.
따라서, 먼저 계산된 결과에서 2를 치환한다고 하더라도, 그 다음에 들어온 쓰레드도 1과 1을 더하기 때문에
다시 amount의 값에 2를 치환한다.
| 쓰레드 - 0 | 쓰레드 - 1 | ||
| 현재 연산 | amount의 값 | 현재 연산 | amount의 값 |
| amount + value | 1 | 다른 작업 중 | |
| 더하기 완료 | 1 | amount + value | 1 |
| 좌측항에 치환 | 2 | 더하기 완료 | 1 |
| 다른 작업 수행 | 좌측항에 치환 | 2 | |
이렇게 동시에 연산이 수행되기 때문에 우리가 원한 20,000이라는 값이 출력되지 않은 것이다.
은행에서도 직원이 한 창구에서 한 고객의 요청만 처리할 수 있다.
만약 한번에 여러 고객의 요청을 처리하려면 해당 창구는 고객의 요청이 뒤죽박죽 되어서 한건도 제대로 처리하기 어렵게 될 것이다.
이러한 문제를 해결하기 위한 것이 바로 싱크로나이즈다.
이제 싱크로나이즈를 plus( ), minus( ) 메소드에 추가하자.
이 synchronized라는 예약어를 하나 추가함으로써, 이 메소드는 동일한 객체를 참조하는 다른 쓰레드에서,
이 메소드를 변경하려고 하면 먼저 돌아온 쓰레드가 종료될 때까지 기다린다.
package e.thread.sync;
public class CommonCalculate {
private int amount;
public CommonCalculate() {
amount = 0;
}
public synchronized void plus( int value ) {
amount += value;
}
public synchronized void minus( int value ) {
amount -= value;
}
public int getAmount() {
return amount;
}
}
만약 plus( ) 에만 synchroinzed를 포함한다면, minus( ) 에서도 방금 살펴본 것과 같은 현상이 발생하게 된다.
이렇게 변경하면, 어떤 쓰레드에서 plus( )나 minus( ) 메소드를 수행하고 있을 때 다른 쓰레드에서 수행하려고 하면,
늦게 온 쓰레드는 앞서 수행하는 메소드가 끝날 때까지 기다리게 된다.
이렇게 변경한 후 결과는 다음과 같다.
Final value is 20000
Final value is 20000
Final value is 20000
Final value is 20000
Final value is 20000
언제 수행하든지, 이 예제가 수행한 결과는 동일한 20,000이라는 결과를 출력한다.
이제 plus( )와 minus( ) 메소드는 쓰레드에 안전하다고 할 수 있다.
STEP#06. 동기화( synchronized ) 블록은 이렇게 사용한다.
위에서 살펴본 것과 같이 메소에 간단히 synchronized를 추가해 주면 되는것으로 보인다.
하지만, 이렇게 하면 성능상 문제점이 발생할 수 있다.
예를 들어 어떤 클래스에 30줄 짜리 메소드가 있다고 가정하자.
그 클래스에 amount라는 인스턴스 변수가 있고, 30줄 짜리 메소드에서 amount라는 변수를 한 줄에서만 다룬다.
만약 해당 메소드 전체를 synchronized로 선언한다면, 나머지 29줄의 처리를 할 때 필요없는 대기 시간이 발생하게 된다.
이러한 경우에는 메소드 전체를 감싸면 필요없는 시간낭비가 발생한다.
따라서, amount라는 변수를 처리하는 부분만 synchronized 처리를 해 주면 된다.
public void plus( int value ) {
synchronized( this ) {
amount += value;
}
}
public void minus( int value ) {
synchronized( this ) {
amount += value;
}
}
이렇게 하면 synchronized( this ) 이후에 있는 중괄호 내에 있는 연산만 동시에 여러 쓰레드에서 처리하지 않겠다는 의미다.
소괄호 안에 this가 있는 부분에는 잠금처리르 하기 위한 객체를 선언한다.
여기서는 그냥 this라고 지정했지만, 일반적으로는 다음과 같이 별도의 객체를 선언하여 사용한다.
Object lock = new Object();
public void plus( int value ) {
synchronized( lock ) {
amount += value;
}
}
public void minus( int value ) {
synchronized( lock ) {
amount -= value;
}
}synchronized를 사용할 때에는 하나의 객체를 사용하여 블록 내의 문장을 하나의 쓰레드만 수행하도록 할 수 있다.
쉽게 생각하자면, 여기서 사용한 lock이라는 객체나, 앞서 사용한 this는 모든 문지기라고 볼 수 있다.
그리고, 그 문지기는 한명의 쓰레드만 일을 할 수 있도록 허용해 준다.
만약 블록에 들어간 쓰레드가 일을 다 처리하고 나오면, 문지기는 대기하고 있는 다른 쓰레드에 기회를 준다.
한 가지 짚고 가자면, 쓰레드와 관련된 예제는 직접 수행해 보지 않는 이상 머리에 쉽게 그 개념이 잡히지 않는다.
한 가지 짚고 넘어가자면, 쓰레드와 관련된 예제는 직접 수행해보지 않는 이상 머리에 쉽게 그 개념이 잡히지 않는다. 따라서, 반드시 예제코드를 작성하고 싫애해 보면서 머리속에 꼭 기억해야 한다.
이렇게, synchronized 블록을 사용할 때에는 lock이라는 별도의 객체를 사용할 수 있다.
그런데, 때에 따라서 이러한 객체는 하나의 클래스에서 두 개 이상만들어 사용할 수도 있다.
만약 클랙스에 amount라는 변수 외에 interest라는 변수가 있고,
그 interest라는 변수를 처리할 때에도 여러 쓰레드에서 접근하면 안된느 경우가 발생할 수 있다.
이럴 때 만약 lock이라는 하나의 잠금용 객체만을 사용하면 amount라는 변수를 처리할 때,
insert라는 변수를 처리하려는 부분도 처리르 못하고 기다려야 한다.
따라서, amount에는 amountLock, interest에는 interestLock을 따로 만들어서 사용하면 보다 효율적인 프로그램이 된다.
private int amount;
private int interest;
public void addInterest( int value ) {
interest += value;
}
public void plus( int value ) {
amount += value;
}
이렇게 되어 있는 상황에서 방금 이야기한 방식을 정요하자면 다음과 같이 지정해 주면 된다.
private int amount;
private int interest;
private Object interestLock = new Object();
private Object amountLock = new Object();
public void addInterest( int value ) {
synchronized( interestLock ) {
interest += value;
}
}
public void plus( int value ) {
synchronized( amountLock ) {
amount += value;
}
}
지금까지 여러 쓰레드에서 동시에 접근했을 때 안전하게 처리하기 위한 synchronized에 대해서 살펴 보았다.
자바 개발자로 살아가기 위해서는 절대로 이 부분은 모르고 지나치면 안된다.
꼭 머리 속에 synchronized에 대한 개념을 넣어 주기 바란다.
synchronized를 사용할 때 잘 하는 실수 한 가지가 있다.
앞서 작성한 RunSync 클래스의 일부 코드를 다시 살펴보자.
CommonCalculate calc = new CommonCalculate();
ModifyAmountThread thread1 = new ModifyAmountThread( calc, true );
ModifyAmountThread thread2 = new ModifyAmountThread( calc, true );
메소드를 synchronized할 때에는 이처럼 calc라는 같은 객체를 참조할 때에만 유효하다.
이 코드를 잘 보자. calc라는 하나의 객체를 사용하여 thread1과 thread2를 생성했다.
만약 두개의 쓰레드가 동일한 clac가 아닌 서로 다른 객체를 참조한다면
synchronized로 선언된 메소드는 같은 객체를 참조하는 것이 아니므로,
synchronized를 안쓰는 것과 동일하다고 보면 된다.
그리고, 또 한가지 주의해야할 사항은,
synchronized는 여러 쓰레드에서 하나의 객체에 있는 인스턴스 변수를
동시에 처리할 때 발생할 수 있는 문제를 해결하기 위해서 필요한 것이라는 점이다.
즉, 인스턴스 변수가 선언되어 있다고 하더라도, 변수가 선언되어 있는 객체를 다른 쓰레드에서 공유할 일이 전혀 없다면
synchronized를 사용할 이유가 전혀 없다. 혹시라도, synchronized를 모든 메소드에 추가할 필요는 없다.
StringBuffer : 쓰레드에 안전
StringBuilder : 쓰레드에 안전하지 않다.
앞에서 String을 배울 때 같이 살펴본 StringBuffer와 StirngBuilder라는 클래스가 있다. 여기서 StringBuffer는 쓰레드에 안전하고, StringBuilder는 쓰레드에 안전하지 않다고 이야기했다. 조금 더 상세히 이야기하자면, StringBuffer는 synchronized 블록으로 주요 데이터 처리 부분을 감싸 두었고, StringBuilder는 synchronized라는 것이 사용되지 않았다. 따라서, StringBuffer는 하나의 문자열 객체를 여러 쓰레드에서 공유해야 하는 경우에만 사용하고, StringBuilder는 여러 쓰레드에서 공유할 일이 없을 때 사용하면 된다. 결론적으로 필요에 따라 적절한 클래스를 선택하여 사용하는것도 매우 중요하며, 그러기위해서는 API문서를 자주 참조하면서 개발해야만 한다.
STEP#07. 쓰레드( Thread )를 통제하는 메소드들
여러 가지 이유로, 쓰레드를 통제해야 하는 경우가 있을 수 있다. 이번에는 쓰레드의 상태를 통제하는 메소드를 살펴보자.
| 메소드 이름 및 매개 변수리 | 턴 타입 | 설명 |
| getState( ) | Thread.State | 쓰레드의 상태를 확인한다. |
| join( ) | void | 수행중인 쓰레드가 중지할 때까지 대기한다. |
| join( long millis ) | void | 매개 변수에 지정된 시간만큼( 1 / 1,000초 ) 대기한다. |
| join( long millis, int nanos ) | void | 첫번째 매개 변수에 지정된 시간( 1 / 1,000초 ) + 두번째 매개 변수에 지정된 시간( 1 / 1,000,000,000초 )만큼 대기한다. |
| interrupt( ) | void | 수행중인 쓰레드에 중지 요청을 한다. |
먼저 getStrate( ) 리턴하는 Thread.State에 대해서 알아보자.
자바의 Thread 클래스에는 State enum 클래스가 있다.
이 클래스에 선언되어 있느 상수들의 목록은 다음과 같다.
| 상태 | 의미 |
| NEW | 쓰레드 객체는 생성되었지만, 아직 시작되지는 않은 상태 |
| RUNNABLE | 쓰레드가 실행중인 상태 |
| BLOCKED | 쓰레드가 실행 중지 상태이며, 모니터 락( monitor lock )이 풀리기를 기다리는 상태 |
| WATTING | 쓰레드가 대기중인 상태 |
| TIMED_WAITING | 특정 시간만큼 쓰레드가 대기중인 상태 |
| TERMINATED | 쓰레드가 종료된 상태 |
이 클래스는 public static으로 선언되어 있다. 다시 말하면, Thread.State.NEW와 같이 사용할 수 있다는 의미다.
그리고, 어떤 쓰레드이건 간에 "NEW → 상태 → TERMINATED"의 라이프 사이클을 가진다.
여기서 "상태"에 해당하는 것은 NEW와 TERMINATED를 제외한 모든 다른 상태를 의미한다.
쓰레드 상태를 다이어그램으로 표시한면 다음과 같다.
이 그림을 보면 어떤 메소드가 호출되면 해당 상태로 전환되는지를 한눈에 볼 수 있을 것이다.
getState( ) 메소드 다음에 join( ) 이라는 메소드가 있다.
이 메소드는 앞서 synchronized에 대해서 배울 때 한번 등장했었다.
join( ) 메소드는 해당 쓰레드가 종료될 때까지 무한대로 기다린다.
만약, 특정 시간만큼만 기다리고 싶다면, join( ) 메소드의 매개 변수에 기다리고 싶은 시간을 지정하면 된다.
이 시간은 밀리초( 1 /1,000 초 ) 단위로 지정하면 되며, 만약 1분간 기다리고 싶다면,
thread.join( 60000 );으로 지정하면 된다.
만약 매개변수 값을 0으로 지정하면 join( ) 메소드를 사용하는 것과 동일하게 무한정 기다리게 된다.
그리고, 더 세밀하게 지정하고 싶다면, 매개 변수가 두 개인 join( ) 메소드를 사용하면 된다.
매개 변수가 두개인 join( ) 메소드의 첫번째 매개변수는 밀리초( 1 / 1,000 초 ) 단위이며,
두번째 매개 변수는 나노초( 1 / 1,000,000,000 초 ) 단위이다.
예를 들어 0.002000003 만큼만 기다리고 싶다면,
thread.join(2, 3);으로 지정하면 된다. 즉, 이렇게 지정하면 2 / 1,000 + 3 / 1,000,000,000 초만큼 기다린다.
따라서 1 밀리초 이하의 시간을 지정하므로 두번째 매개 변수에는 0 ~ 999,9999까지만 지정하면 된다.
만약, 첫번째 매개 변수가 음수이거나, 두번째 매개 변수가 0 ~ 999,999 사이의 값이 아니면,
IllegalArgumentException이라는 예외가 발생하게 된다.
이번에는 interrupt( ) 메소드에 대해서 살펴보자.
interrupt( ) 메소드는 현재 수행중인 쓰레드를 중단시킨다.
그런데, 그냥 중지시키지는 않고, InterruptedException을 발생시키면서 중단시킨다.
이 예외는 앞서 sleep( )과 join( ) 메소드에서 발생한다고 했던 예외다.
즉, sleep( )과 join( ) 메소드와 같이 대기 상태를 만드는 메소드가 호출되었을 때에는 interrupt( ) 메소드를 호출할 수 있다.
이 외에도, Object 클래스의 wait( ) 메소드가 호출된 상태에서도 이 메소드를 사용할 수 있다.
wait( ) 메소드에 대해서는 조금 있다가 다시 살펴볼 것이다.
만약 쓰레드가 시작하기 전이나, 종료된 상황에 interrupt( ) 메소드를 호출하면 어떻게 쓸까?
그러한 상황에서는 예외나 에러 없이 그냥 다음 문장으로 넘어간다.
추가로, 자바의 Thread 클래스에는 stop( ) 이라는 메소가 있다.
stop( ) 메소드는 안전상의 이유로 deprecated되었으며, 이 메소드를 사용하면 안된다.
그러므로, interrupt( ) 메소드를 사용하여 쓰레드를 멈추어야 한다.
그러면, 지금까지 배운 메소드들을 예제를 통해서 살펴보자,
먼저 매개 변수로 지정한 시간만큼 대기하는 쓰레드를 다음과 같이 만들자.
package e.thread;
public class SleepThread extends Thread {
long sleepTime;
public SleepThread( long sleepTime ) {
this.sleepTime = sleepTime;
}
pbulc void run() {
try {
System.out.println( "Sleeping " + getName() );
Thread.sleep( sleepTiem );
System.out.println( "Stopping " + getName() );
}
catch( InterruptedException ie ) {
ie.printStackTrace();
}
}
}
생성자를 보면 sleepTime이라는 밀리초 단위의 시간을 매개 변수로 받아서 인스턴스 변수에 지정해 놓고,
run( ) 메소드에서 그 시간만큼 잠을 자는 것을 볼 수 있다.
그리고, 쓰레드가 sleep( ) 메소드 때문에 잠자기 전과 후에 출력문을 놓아 두어 상태가 변할 때를 알 수 있도록 해 놓았다.
이제 RunThreads 클래스에 다음의 메소드를 추가한 후 main( ) 메소드에서 이 메소드만 수행하도록 해놓자.
public void checkThreadState1() {
// SleepThread의 생성자 매개 변수에 2000이라는 값을 넘겨줌으로써,
// 해당 쓰레드가 2초 동안 대기하도록 선언했다.
SleepThread thread = new SleepThread( 2000 );
try {
// 앞서 배운 상태 확인을 위한 getState() 메소드를 사용하여 각 상황별 상태를 출력하도록 했다.
System.out.println( "thread state = " + thread.getState() );
thread.start();
System.out.println( "thread state( after start ) ) = " + thread.getState() );
// sleep() 메소드를 사용하여 쓰레드가 시작하고 1초 동안 대기한 후의 상태를 출력도록 했다.
Thread.sleep( 1000 );
System.out.println( "thread state( after 1sec ) = " + thread.getState() );
// join() 메소드를 사용하여, 메소드가 끝날 때까지 기다리도록 했다.
thread.join();
// 쓰레드가 종료된 이후에 interrupt() 메소드를 호출했다.
thread.interrupt();
System.out.println( "thread state( after join ) = " + thread.getState() );
}
catch( InterruptedException ie ) {
ie.printStackTrace();
}
}
출력되는 결과는 다음과 같다.
// 아직 쓰레드가 시작한 상황이 아니다. 따라서, Thread.State 중 NEW 상태다.
thread state = NEW
// 쓰레드가 시작한 상황이며 아직 첫 출력문까지 도달하지 않았으므로, RUNNABLE 상태다.
thread state( after start ) = RUNNABLE
Sleeping Thread-0
// 2초간 잠자는 모드가 되어야 하므로, TIMED_WAITING 상태다.
thread state( after 1 sec ) = TIMED_WAITING
Stopping Thread-0
// 쓰레드가 종료되기를 join() 메소드에서 기다린 후의 상태이므로, TERMINATED 상태다.
thread state( after join ) = TERMINATED
그러면, 방금 살펴본 예제의 join( ) 메소드 부분을 다음과 같이 변경해보자.
// thread.join();
thread.join( 500 );
thread.interrupt();
이렇게 변경한 후에 실행결과는 thread가 2초간 대기하기 때문에 checkThreadState1( ) 메소드에서는 총 1.5초를 대기하게 된다.
따라서, thread가 종료하지 않은 상태다. 그러므로, interrupt( ) 메소드가 수행되고 해당 쓰레드가 중지된다.
그러므로, 다음과 같은 결과가 출력된다.
thread state = NEW
thread state( after start ) = RUNNABLE
Sleeping Thread-0
thread state( after 1 sec ) = TIMED_WATING
thread state( after join ) = TIMED_WATING
java.lang.InterruptedException : sleep interrupted
at java.lang.Thread.sleep( Native Method )
at e.thread.SleepThread.run( SleepThread.java:11 )
이렇게 잠자고 있던 쓰레드가 멈추고, InterruptedException 이라는 것이 발생한 것을 볼 수 있다.
다시 join( ) 메소드의 매개 변수의 값을 "500"이 아닌 "1100"으로 지정해보자.
이 경우에는 2초 이상 대기했으므로, 해당 쓰레드는 종료된다.
따라서, 이미 끝난 쓰레드에 interrupt( ) 메소드를 호출해봤자 안무런 반응을 보이지 않으므로,
다음과 같이 정상적인 결과를 출력한다.
thread state = NEW
thread state( after start ) = RUNNABLE
Sleeping Thread-0
thread state( after 1 sec ) = TIMED_WATING
Stopping Thread-0
thread state( after join ) = TERMINATED이렇게 예제를 통해서 살펴보면, 조금 더 join( )과 interrupt( ) 메소드에 대해서 잘 이해가 될 것이다.
이 메소드들 외에 Thread 클래스에 선언되어 있는 상태 확인을 위한 메소드는 다음과 같다.
| 메소드 이름 및 매개변수 | 리턴타입 | 설명 |
| checkAccess( ) | void | 현재 수행중인 쓰레드가 해당 쓰레드를 수정할 수 있는 권한이 있는지를 확인한다. 만약 권한이 없다면 SecurityException이라는 예외를 발생시킨다. |
| isAlive( ) | boolean | 쓰레드가 살아 있는지를 확인한다. 해당 쓰레드의 run( ) 메소드가 종료되었는지 안 되었는지를 확인하는 것이다. |
| isInterrupted( ) | boolean | run( ) 메소드가 정상적으로 종료되지 않고, interrupt( ) 메소드의 호출을 통해서 종료되었는지를 확인하는 데 사용한다. |
| isInterrupted( ) | static boolean | 현재 쓰레드가 중지되었는지를 확인한다. |
interrupted( ) 메소드를 잘 살펴보면 static 메소드이기 때문에 현재 쓰레드가 종료되었는지를 확인할 때 사용한다.
isInterrupted( ) 메소드는 다른 쓰레드에서 확인할 때 사용되고,
interrupted( ) 메소드는 본인의 쓰레드를 확인할 때 사용된다는 점이 다르다.
그런데, 왜 interrupted( )나 isInterrupted( )라는 메소드가 필요할까?
앞에서 interrupted( ) 메소드는
쓰레드가 join( ), sleep( ), wait( ) 메소드를 호출해 놓은 상태에서만 쓰레드를 중단한다고 이야기 했다.
다시 말해서, 그 외의 상태에서는 아무리 interrupt( ) 메소드를 호출해도 해당 쓰레드는 중단되지 않는다.
이 내용을 확인해 보기 위해서 예제를 살펴보자. 다음과 같이 무한 루프를 수행하는 쓰레드가 있다.
package e.thread;
import java.util.HashMap;
import java.util.Hashtable;
public class InfiniteThread extends Thread {
public void run() {
while( true ) {
String str = "String.";
new HashMap( 10000 );
new Hashtable( 10000 );
}
}
}
이 스레드는 문자열과 HashMap, Hashtable 객체를 while 문 안에서 지속적으로 생성한다.
이럴 때 해당 코드는 자동으로 중단되지 않는다.
RunThreads 클래스에 다음과 같이 infinite( ) 메소드를 만들자.
public void infinite() {
InfiniteThread thread = new InfiniteThread();
thread.start();
try {
Thread.sleep( 500 );
thread.interrupt();
System.out.println( "interrupt() called" );
thread.join( 500 );
}
catch( InterruptedException ie ) {
ie.toString();
}
System.out.println( "isAlive = " + thread.isAlive() );
System.out.println( "isInterrupted = " + thread.isInterrupted() );
}InfiniteThread 클래스의 객체를 만들어 실행한 후 interrupt( ) 메소드가 호출된 것을 볼 수 있다.
그 다음엔 join( ) 메소드를 사용하여 0.5초간 대기하고, 해당 쓰레드가 살아 있는지, 중단되었는지를 확인한다.
infinite( ) 메소드만 실행하도록 RunThreads 클래스의 main( ) 메소드를 변경한 후 실행해보자.
결과는 다음과같이 출력되며, InfiniteThread가 종료되지 않기 때문에 해당 프로그램은 계속 실행되고 있을 것이다.
Ctrl + c를 눌러 해당 쓰레드를 멈추자.
interrupt() called
isAlive = true
isInterrupted = true
출려된 결과를 보면 해당 쓰레드는 살아있기도 하지만, isInterrupted( )결과도 true다.
이 예제를 살펴보기 바로 전에 필자가 이야기한 내용을 다시 한번 상기해 보자.
interrupt( ) 메소드는 join( ), sleep( ), wait( ) 메소드가 호출된 상태에서만 쓰레드를 중단시킨다고 했다.
만약 어플리케이션의 다른 메소드가 계속 실행중이고, 이세개의 메소드 중 하나가 호출되지 않으면
아무리 interrupt( )를 호출해도 전혀 효과가 없다. 즉, 멈추지 않는다.
InfiniteThread 클래스의 run( ) 메소드를 다음과 같이 수정하자.
public void run() {
while( true ) {
String str = "String.";
new HashMap( 10000 );
new Hashtable( 10000 );
if( Thread.interrupted() ) { return; }
}
}
interrupted( ) 메소드가 사용된 것을 볼 수 있다.
이렇게 변경한 후 다시 컴파일을 해보면 출력되는 결과는 다음과 같다.
interrupt() called
isAlive = false
isInterrupted = false
앞에서는 모든 is로 시작하는 메소드의 수행 결과가 true 였었지만, 지금은 모두 false다.
게다가, 해당 프로그램은 무한 루프를 돌지 않고, 멈추어 버린다.
isAlive( ) 메소드의 결과가 false인 이유는 해당 쓰레드가 멈추었기 때문이며,
isInterrupted( ) 메소드의 결과가 false인 이유는 interrupt 되기는 했지만,
이미 쓰레드가 중지된 이후이기 때문에 false를 리턴한다.
지금까지 살펴본 Thread 클래스에서 제공하는 메소드는 쓰레드를 생성하고 처리하는데 사용되었다.
추가적으로 JVM에서 사용되는 쓰레드의 상태들을 확인하기 위해서는 Thread 클래스의 static 메소드들을 알아야만 한다.
| 메소드 이름 및 매개 변수 | 리턴 타입 | 설명 |
| activeCount( ) | static int | 현재 쓰레드가 속한 쓰레드 그룹의 쓰레드 중 살아있는 쓰레드의 개수를 리턴한다. |
| currentThread( ) | static Thread | 현재 수행중인 쓰레드의 객체를 리턴한다. |
| dumpStack( ) | static void | 콘소 창에 현재 쓰레드의 스택 정보를 출력한다. |
지금까지 Thread 클래스에 선언되어 있는 주요 메소드들을 살펴보았다.
그런데, Thread 클래스에 선언되어 있는 메소드들 외에 Object 클래스에 있는 메소드들도 쓰레드를 통제하는데 사용된다.
STEP#08. Object 클래스에 선언된 쓰레드와 관련있는 메소드들
Thread 클래스에 선언된 메소드 외에 쓰레드의 상태를 통제하는 메소드가 있다.
바로 Object 클래스들에 선언되어 있는 메소드들이다.
| 메소드 이름 및 매개 변수 | 리턴 타입 | 설명 |
| wait( ) | void | 다른 쓰레드가 Object 객체에 대한 notify( ) 메소드나 notifyAll( ) 메소드를 호출할 때까지 현재 쓰레드가 대기하고 있도록 한다. |
| wait( long timeout ) | void | wait( ) 메소드와 동일한 기능을 제공하며, 매개 변수에 지정한 시간만큼만 대기한다. 즉, 매개 변수 시간을 넘어 섰을 때에는 현재 쓰레드는 다시 깨어난다. 여기서의 시간은 밀리초 1 / 1,000초 단위다. 만약 1초간 기다리게 할 수 경우에는 1000을 매개 변수로 넘겨주면된다. |
| wait( long timeout, int nanos ) | void | wait( ) 메소드와 동일한 기능을 제공한다. 하지만, wait( timeout )에서 밀리초 단위의 대기시간을 기다린다면, 이 메소드는 보다 자세한 밀리초 + 나노초( 1 / 1,000,000,000 초 ) 만큼만 대기한다. 뒤에 잇는 나노초의 값은 0 ~ 999,999 사이의 값만 지정할 수 있다. |
| notify( ) | void | Object 객체의 모니터에 대기하고 있는 단일 쓰레드를 깨운다. |
| notifyAll( ) | void | Object 객체의 모니터에 대기하고 있는 모든 쓰레드를 깨운다. |
※ 여기서 "모니터"라는 것은 PC의 화면을 이야기 하는것이 아니라, 앞서 살펴본
lock 객체와 같이 쓰레드가 안전하게 수행하도록 도와주는 객체를 의미한다.
설명을 보면 매우 어렵게 느껴지겠지만, 간단하게 이야기하면 wait( ) 메소드를 사용하면 쓰레드가 대기 상태가 되며,
notify( )나 notifyAll( ) 메소드를 사용하면 쓰레드의 대기 상태가 해제된다.
예제를 봐야 wait( )와 notify( ) 메소드에 대해서 이해가 쉬울 것이다.
다음과 같은 StateThread 클래스를 만들자.
package e.thread;
public class StateThread extends Thread {
private Object monitor;
// monitor라는 이름의 객체를 매개 변수로 받아 인스턴스 변수로 선언해 두었다.
public StateThread( Object monitor ) {
this.monitor = monitor;
}
public void run() {
try {
// 쓰레드를 실행중인 상태로 만들기 위해서 간단하게 루프를 돌면서 String 객체를 생성한다.
for( int loop = 0; loop < 10000; loop++ ) {
String a = "A";
}
synchronized( monitor ) {
// synchronized 블록 안에서 monitor 객체의 wait() 메소드를 호출했다.
monitor.wait();
}
System.out.println( getName() + " is notified." );
// wait() 상황이 끝나면 1초간 대기햇다가 이 쓰레드는 종료한다.
Thread.sleep( 1000 );
}
catch( InterruptedException ie ) {
ie.printStackTrace();
}
}
}
이제 이 쓰레드를 실행하는 메소드를 RunThreads 클래스에 다음과 같이 만들어보자.
public void checkThreadState2() {
// StateThread의 매개 변수로 넘겨줄 monitor라는 Object 클래스 객체를 생성한다.
Object monitor = new Object();
StateThread thread = new StateThread( monitor );
try {
System.out.println( "thread state = " + thread.getState() );
// 쓰레드 객체를 생성하고 시작한다.
thread.start();
System.out.println( "thread state( after start ) = " + thread.getState() );
Thread.sleep( 100 );
System.out.println( "thread state( after 0.1 sec ) = " + thread.getState() );
synchronized( monitor ) {
// monitor 객체를 통하여 notify() 메소드를 호출한다.
monitor.notify();
}
Thread.sleep( 100 );
System.out.println( "thread state( after notify ) = " + thread.getState() );
// 쓰레드가 종료도리 때까지 기다린 후 상태를 출력한다.
thread.join();
System.out.println( "thread state( after join ) = " + thread.getState() );
}
catch( InterruptedException ie ) {
ie.printStackTrace();
}
}
이 메소드들 실행하면 어떤 결과가 나올지 생각해 보자.
출력결과는 다음과 같다.
thread state = NEW
thread state( after start ) = RUNNABLE
thread state( after 0.1 sec ) = WAITING -- 1
Thread-0 is notified.
thread state( after notify ) = TIMED_WAITING
thread state( after join ) = TERMINATED
1에서 보는 것과 같이 wait( ) 메소드가 호출되면, 쓰레드의 상태는 WAITING 상태가 된다.
따라서, 누군가가 이 쓰레드를 깨워 줘야만 이 WAITING 상태에서 풀린다. 마치 잠자는 숲속의 공주처럼 말이다.
interrupt( ) 메소드를 호출하여 대기 상태에서 풀려날 수도 있겠지만,
notify( ) 메소드를 호출해서 풀어야 InterruptedException도 발생하지 않고,
wait( ) 이후의 문장도 정상적으로 수행하게 된다.
다시 말해서, notify( ) 메소드가 잠자는 숲속의 공주에게 키스를 하는 작업이라고 보면 된다.
방금 살펴본 checkThreadState2( ) 메소드를 복사하여 checkThreadState3( ) 라는 메소드를 만들자.
그리고, 다음과 같이 하나의 쓰레드를 더 실행하도록 소스를 약간 수정하자.
public void checkThreadState3() {
Object monitor = new Object();
StateThread thread = new StateThread( monitor );
StateThread thread2 = new StateThread( monitor );
try {
System.out.println( "thread state = " + thread.getState() );
thread.start();
thread2.start();
System.out.println( "thread state( after start ) = " + thread.getState() );
Thread.sleep( 100 );
System.out.println( "thread state( after 0.1 sec ) = " + thread.getState() );
synchronized( monitor ) {
monitor.notify();
}
Thread.sleep( 100 );
System.out.println( "thread state( after notify ) = " + thread.getState() );
thread.join();
System.out.println( "thread state( after join ) = " + thread.getState() );
thread2.join();
System.out.println( "thread2 state( after join ) = " + thread2.getState() );
}
catch( InterruptedException ie ) {
ie.printStackTrace();
}
}thread2라는 쓰레드 객체를 하나 더 생성한 후 동시에 실행하도록 해 놓았다.
그리고, 다른 점이라면, thread2.join( ) 부분을 추가하여 thread2가 끝날 때까지 대기한 후 상태를 출력한다.
이제 main( ) 메소드에서 checkThreadState3( ) 메소드만 실행하도록 변경한 후 결과를 살펴보자.
thread state = NEW
thread state( after start ) = RUNNABLE
thread state( after 0.1 sec ) = WAITING
Thread-0 is notified.
thread state( after notify ) = TIMED_WAITING
thread state( after join ) = TERMINATED아무 생각 없이 이 출력 결과를 보면 이상이 없다고 생각할 수도 있다.
하지만, thread2는 notify되지 않았고, 끝나지도 않았다.
왜냐하면, 자바에서 notify( ) 메소드를 호출하면, 먼저 대기하고 있는 것부터 그 상태를 풀어주기 때문이다.
좀 무식하게 풀어주려면 다음과 같이 synchronized 블록을 수정해주면 된다.
synchronized( monitor ) {
monitor.notify();
monitor.notify();
}
이렇게 하면 두개의 쓰레드 모두 wait( ) 상태에서 풀린다.
그런데, monitor 객체를 통해서 wait( ) 상태가 몇 개인지 모르는 상태에서는 이와 같이 구현하는 것은 별로 좋은 방법은 아니다.
그래서, 이럴 때에는 다음과 같이 notifyAll() 메소드를 사용하는 것이 좋다.
synchronized( monitor ) {
// monitor.notify();
// monitor.notify();
monitor.notifyAll();
}
그러면 monitor 객체를 통해서 대기중인 모든 쓰레드에게 notify( )를 전달하는 것과 동일한 결과를 제공해준다.
이렇게 변경한 후 실행하면 다음과 같이 결과가 출력된다.
thread state = NEW
thread state( after start ) = RUNNABLE
thread state( after 0.1 sec ) = WAITING
Thread-0 is notified.
Thread-1 is notified.
thread state( after notify ) = TIMED_WAITING
thread state( after join ) = TERMINATED
thread2 state( after join ) = TERMINATED
추가로, 예제를 통해서 다루지는 않았지만, wait( ) 메소드는 join( ) 메소드처럼 매개 변수에 대기 시간을 지정하여
특정 기간 동안에만 대기하라고 할 수도 있으니 참고하기 바란다.
STEP#09. ThreadGroup에서 제공하는 메소드들
앞에서 쓰레드 객체를 생성할 때 지정하는 ThreadGroup 클래스에 대해 살펴보자.
ThreadGroup은 쓰레드의 관리를 용이하게 하기 위한 클래스다.
하나의 어플리케이션에는 여러 종류의 쓰레드가 있을 수 있으며,
만약 ThreadGroup 클래스가 없으면 용도가 다른 여러 쓰레드를 관리하기 어려울 것이다.
쓰레드 그룹은 기본적으로 트리( tree ) 구조를 가진다.
즉, 하나의 그룹이 다른 그룹에 속할 수도 있고, 그 아래에 또 다른 그룹을 포함할 수도 있다.
먼저 ThreadGroup 클래스에서 제공하는 주요 메소드를 살펴보자.
| 메소드 이름 및 매개 변수 | 리턴 타입 | 설명 |
| activeCount( ) | int | 실행중인 쓰레드의 개수를 리턴한다. |
| activeGroupCount( ) | int | 실행중인 쓰레드 그룹의 개술르 리턴한다. |
| enumerate( Thread[] list ) | int | 현재 쓰레드 그룹에 있는 모든 쓰레드를 매개변수로 넘어온 쓰레드 배열에 담는다. |
| enumerate( Thread[] list, boolean recurse ) | int | 현재 쓰레드 그룹에 있는 모든 쓰레드를 매개변수로 넘어온 쓰레드 배열에 담는다. 두번째 매개변수가 true이면 하위에 있는 쓰레드 그룹에 있는 쓰레드 목록도 포함한다. |
| enumerate( ThreadGroup[] list ) | int | 현재 쓰레드 그룹에 있는 모든 쓰레드 그룹을 매개 변수로 넘어온 쓰레드 그룹 배열에 담는다. |
| enumerate( ThreadGroup[] list, boolean recurse ) | int | 현재 쓰레드 그룹에 있는 모든 쓰레드 그룹을 매개 변수로 넘어온 쓰레드 그룹 배열에 담는다. 두번째 매개 변수가 true이면 하위에 있는 쓰레드 그룹 목록도 포함한다. |
| getName( ) | String | 쓰레드 그룹의 이름을 리턴한다. |
| getParent( ) | ThreadGroup | 부모 쓰레드 그룹을 리턴한다. |
| list( ) | void | 쓰레드 그룹의 상세 정보를 출력한다. |
| setDaemon( boolean daemon ) | void | 지금 쓰레드 그룹에 속한 쓰레드들을 데몬으로 지정한다. |
대부분의 메소드는 표에 있는 내용만 보더라도 이해가 쉽게 될 것이다.
여기서 enumerate( ) 라는 메소드가 있다.
이 메소드는 해당 쓰레드 그룹에 포함된 쓰레드나 쓰레드 그룹의 목록을 매개 변수로 넘어온 배열에 담는다.
이 메소드의 리턴 값은 배열에 저장된 쓰레드의 개수다.
따라서, 쓰레드 그룹에 있는 모든 쓰레드의 객체를 제대로 담으려면
activeCount( ) 메소드를 통해서 현재 실행중인 쓰레드의 개수를 정확히 파악한 후, 그 개수만큼의 배열을 생성하면 된다.
여기에 있는 메소드들을 사용하여 쓰레드 그룹을 생서앟고 그 정보를 확인하는 쓰레드의 마지막 예제를 살펴보자.
아래의 메소드를 RunThreads 클래스에 추가한 후 main( ) 메소드에서 이 메소드만 수행하도록 하자.
public void groupThread() {
try {
SleepThread sleep1 = new SleepThread( 5000 );
SleepThread sleep2 = new SleepThread( 5000 );
ThreadGroup = new ThreadGroup( "Group1" );
Thread thread1 = new Thread( group, sleep1 );
Thread thread2 = new Thread( group, sleep2 );
thread1.start();
thread2.start();
Thread.sleep( 1000 );
System.out.println( "Group name = " + group.getName() );
int activeCount = group.activeCount();
System.out.println( "Active count = " + activeCount );
group.list();
Thread[] tempThreadList = new Thread[ activeCount ];
int result = group.enumerate( tempThreadList );
System.out.println( "Enumerate result = " + result );
for( Thread thread : tempThreadList ) {
System.out.println( thread );
}
}
catch( Exception e ) {
e.printStackTrace();
}
}
메소드의 길이가 좀 길어서 그렇지 그리 어려운 내용들은 아니다.
실행하면 결과는 다음과 같이 출력된다.
Sleeping Thread-0
Sleeping Thread-1
Group name = Group1
Active count = 2
java.lang.ThreadGroup[ name = Group1, maxpri = 10 ]
Thread[ Thread-2, 5, Group1 ]
Thread[ Thread=3, 5, Group1 ]
Enumerate result = 2
Thread[ Thread-2, 5, Group1 ]
Thread[ Thread-3, 5, Group1 ]
Stopping Thread-0
Stopping Thread-1
1과 2에서 쓰레드 그룹 이름과 실행중인 쓰레드 개수를 확인할 수 있다.
그 다음 세줄 3은 list( ) 메소드를 호출했을 때의 결과이다.
4의 결과를 보면 enumerate( ) 메소드 수행 결과 2개의 데이터가 배열에 저장되었으며,
그 다음 두 줄에는 각 쓰레드에 대한 정보가 출력된 것을 볼 수 있다.
이렇게 쓰레드 그룹을 사용하면 쓰레드를 보다 체계적으로 관리할 수 있다.
STEP#10. 각 쓰레드에서 혼자 쓸수 있는 값을 가지는 ThreadLocal
앞에서 여러 쓰레드에서 데이터를 공유할때 발생하는 문제를 해결하기 위해서, synchronized라는 구문을 사용햇다.
만약 쓰레드 별로 서로 다른 값을 처리해야 하는 필요가 있을 경우에는 어떻게 해야 할까?
그 때에는 ThreadLocal 이라는 것을 사용하면 된다.
ThreadLocal에 대해서 자세한 설명을 알아보기 전에 먼저 예제를 보자.
다음과 같이 ThreadLocalSample 클래스를 만들자.
package e.thread;
import java.util.Random;
public class ThreadLocalSample {
// local이라는 ThreadLocal 객체를 생성했다.
// ThreadLocal은 제네릭하게 되어 있는 클래스다.
// 이 클래스의 객체를 생성하기 위해서는 이와 같이 각 쓰레드에서 고유하게 사용할 데이터 타입을 지정해 줘야 한다.
// 이 예제에서는 간단하게 값을 하나 저장하기 때문에 Integer를 사용했다.
private final static ThreadLocal<Integer> local = new ThreadLocal<Integer>();
private static Random random;
static {
random = new Random();
}
public static Interger generateNumber() {
int value = random.nextInt( 45 );
// ThreadLocal 클래스의 set() 메소드를 사용하여 저장하고자 하는 값을 할당한다.
local.set( value );
return value;
}
public static Integer get() {
// ThreadLocal 클래스의 get() 메소드를 사용하여 값을 꺼낸다.
return local.get();
}
public static void remove() {
// local 객체에 저장되어 있는 값을 제거하기 위해서 remove() 메소드를 사용한다.
local.remove();
}
}
만약 ThreadLocal 클래스를 확장하여 사용하려고 할 때에는 initialValue() 라는 메소드를 Override 하여 초기값을 지정할 수 있지만,
여기서는 별도로 확장한 클래스를 만들지 않았다.
ThreadLocal 클래스에서 사용한 set( ), get( ), remove( ) 메소드와 initialValue( ) 메소드가 전부다.
보면 알겠지만 이 코드에는 어떤 synchronized 메소드가 존재하지 않는다.
임의의 값을 생성해 주는 Random 클래스와 nextInt( ) 메소드는 굳이 설명하지 않아도 이해할 수 있을 것이다.
다음과 같이 방금 만든 ThreadLocalSample 클래스를 사용하는 LocalUserThread를 만들자.
package e.thread;
public class LocalUserThread extends Thread {
public void run() {
// 간단하게 ThreadLocalSample의 generateNumber() 메소드만 호출함으로써
// 임의의 변수를 ThreadLocal에 저장하고 리턴 받았다.
int value = ThreadLocalSample.generateNumber();
System.out.prinln( this.getName() + " LocalUserThread value = " + value );
OtherLogic otherLogic = new OtherLogic();
// OtherLogic이라는 클래스에 있는 printMyNumber라는 메소드를 호출한다.
otherLogic.printMyNumber();
// ThreadLocal에서 값을 지운다.
ThreadLocalSample.remove();
}
}
여기서 호출한 OtherLogic 클래스는 다음과 같다.
package e.thread;
public class OtherLogic {
public void printMyNumber() {
System.out.println(
Thread.currentThread().getName() + " OtherLogic value = " + ThreadLocalSample.get()
);
}
}
OtherLogic 클래스에서는 현재 쓰레드의 이름과 ThreadLocalSample 클래스의 get( ) 메소드를 사용하여 값을 읽는다.
만약 임의로 만든 값을 ThreadLocal을 사용하지 않고 OtherLogic 클래스에서 사용하려면 어떻게 해야 할까?
ThreadLocal을 사용하지 않는다면, printMyNumber() 메소드를 호출할 때 매개변수로 넘겼을 것이다.
이렇게 사용해도 된다. 그런데, OtherLogic에서 호출하는 다른 메소드에서 이 값을 사용하려면,
그 메소드에도 이 값을 또 매개 변수로 전달해 줘야만 할것이다.
또 다른 방법은 LocalUserThread 클래으세어 인스턴스 변수를 선언하여 사용하는 방법이 있다.
하지만 ,이 방법 또한 구현이 매우 복잡해질 수 있다.
RunThread 클래스에 다음과 같이 LocalUserThread 객체를 생성하여 실행하는 메소드를 추가하고
main() 메소드에서 이 메소드만 수행하도록 변경하자.
public void runLocalUserThread() {
LcalUserThread threads[] = new LocalUserThread[3];
for( LocalUserThread thread : threads ) {
thread = new LocalUserThread();
thread.start();
}
}
3개의 쓰레드 객체를 생성하여 시작하도록 해 놓았다.
이 코드를 수행한 결과는 다음과 같다.
Thread-1 LocalUserThread value = 33
Thread-1 OtherLogic value = 33
Thread-2 LocalUserThread value = 23
Thread-2 OtherLogic value = 23
Thread-3 LocalUserThread value = 5
Thread-3 OtherLogic value = 5
당연한 이야기지만 이 값은 항상 다르게 나올것이다.
위 결과값에서 유념해서 봐야할 부분은 LoLocalUserThread에서 출력한 값과 OtherLogic에서 출력한 값이 동일하다는 것이다.
게다가 그 값은 각 스레드별로 절대 공유하지 않는다는 것이다.
ThreadLocal에 대해서 한번 정리해보자.
- ThreadLocal에 저장된 값은 해당 쓰레드에서 고유하게 사용할 수 있다.
- ThreadLocal 클래스의 변수는 private static final로 선언한다.
- ThreadLocal 클래스에 선언되어 있는 메소드는 set( ), get( ), remove( ), initialValue( )가 있다.
- 사용이 끝난 후에는 remove( ) 메소드를 호출해 주는 습관을 가져아면 한다.
그런데, 왜 마지막에 있는 remove( ) 메소드를 호출해 줘야 할까?
예제에서 사용한 쓰레드들은 한번 생성되고 수행이 끝나면 사라진다.
하지만, 웹 기반의 어플리케이션에선느 쓰레드를 재사용하기 위해서 쓰레드 풀( ThreadPool )이라는 것을 사용한다.
이 쓰레드 풀을 사용하면 쓰레드가 시작된 후에 그냥 끝나느 것이 아니기 때문에
remove( ) 메소드를 사용하여 값을 지워줘야지만 해당 쓰레드를 다음에 사용할 때 쓰레기 값이 들어있지 않게 된다.
STEP#11. 자바의 volatile
원문 : https://roadbook.co.kr/102
[신간소개] 자바의 신 Vol.2, 주요 API 응용편
● 저자: 이상민 ● 감수: 김성박, 박재성 ● 페이지: 680 ● 판형: 4X6배판(188 x 257) ● 도수: 2도 ● 정가: 27,000원 ● 발행일: 2013년 4월 26일 ● ISBN: 978-89-97924-04-2 93000 [절판!!!!!!!!!] [강컴]..
roadbook.co.kr